Hi! I'm Aspen.
I'm a PhD student at CSAIL in the Madry Lab and the Center for Deployable Machine Learning.
I study how machine learning systems are built and deployed.
AI Supply Chains as Systems
I study how chaining or otherwise composing models & data through "AI supply chains" introduces new challenges to AI development + how we can build tools to help.
Interpretability through Representations
I use internal model representations (like weights or activations) as semantic interfaces for understanding and steering model behavior.
Human‑Centered Tooling
I work on interactive tools, visual interfaces, and policy-relevant artifacts that help people make sense of complex data and computational systems.
research
* * * ai supply chains as systems * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * *
selected
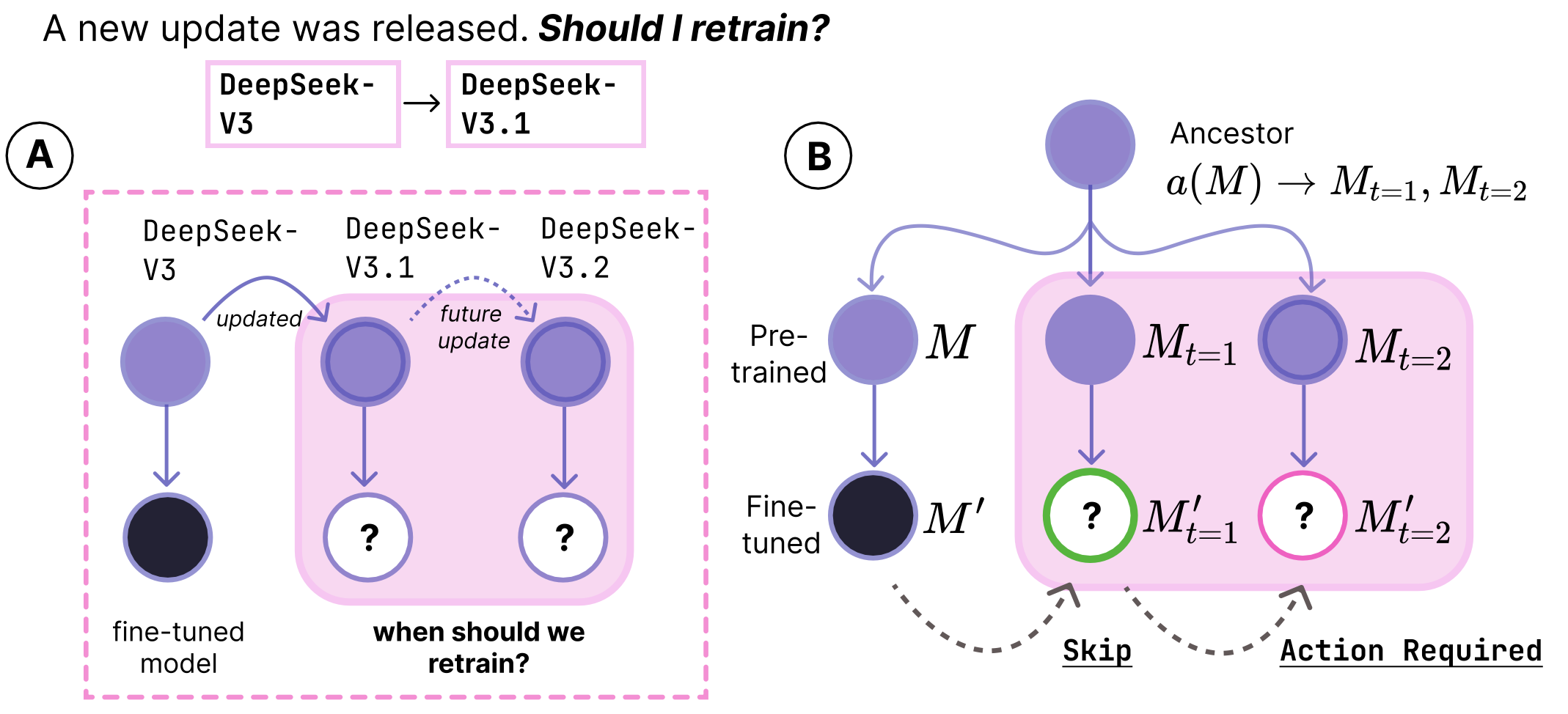
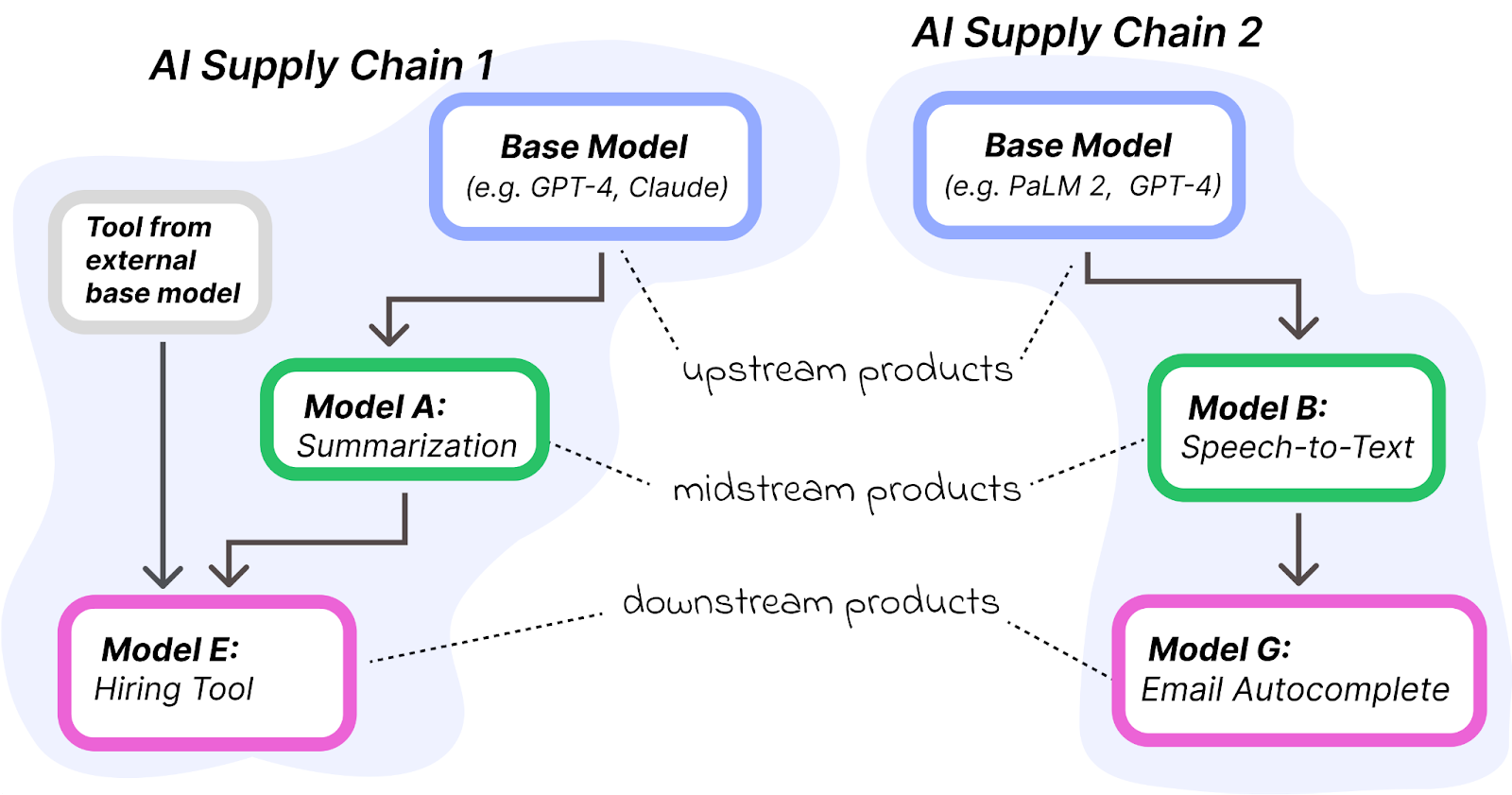
when should model updates propegate?
A new algorithmic challenge for developers has surfaced: deciding when
to adopt model updates. Currently, the only reliable approach is to retrain on new
upstream models and then test extensively. We introduce a method for assessing when to propagate newly released model
versions to downstream applications that does not require access to upstream
data or retraining a priori.
selected
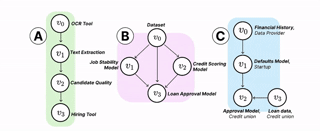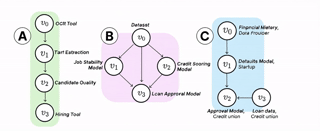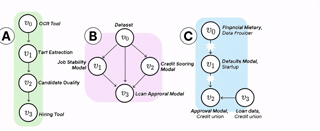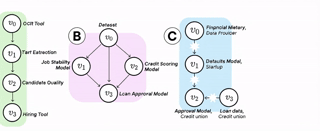
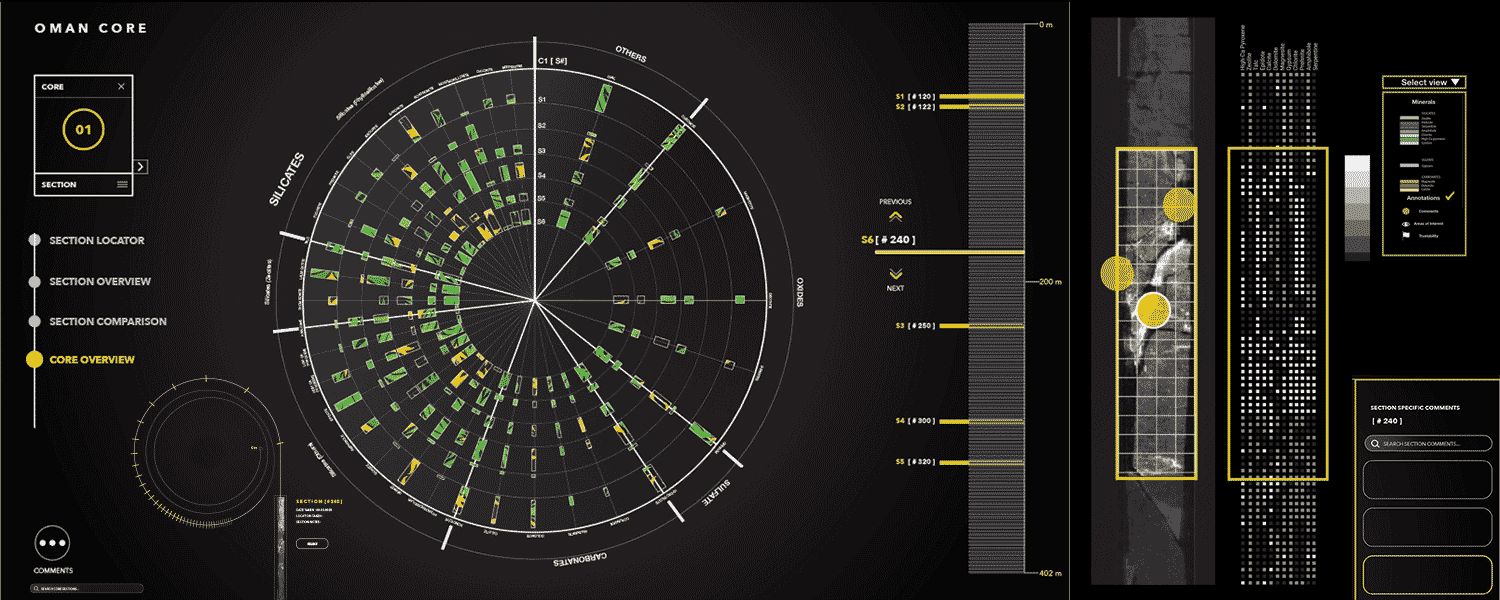
ai supply chains
AI systems are increasingly built and deployed through AI supply chains (AISCs): complex networks of AI components "glued together" by researchers and developers. These supply chains challenge many of the basic expectations we have about ML development and deployment. We provide a formal model of AI supply chains as directed graphs to study how structure and complexity affect fairness and explainability.
selected
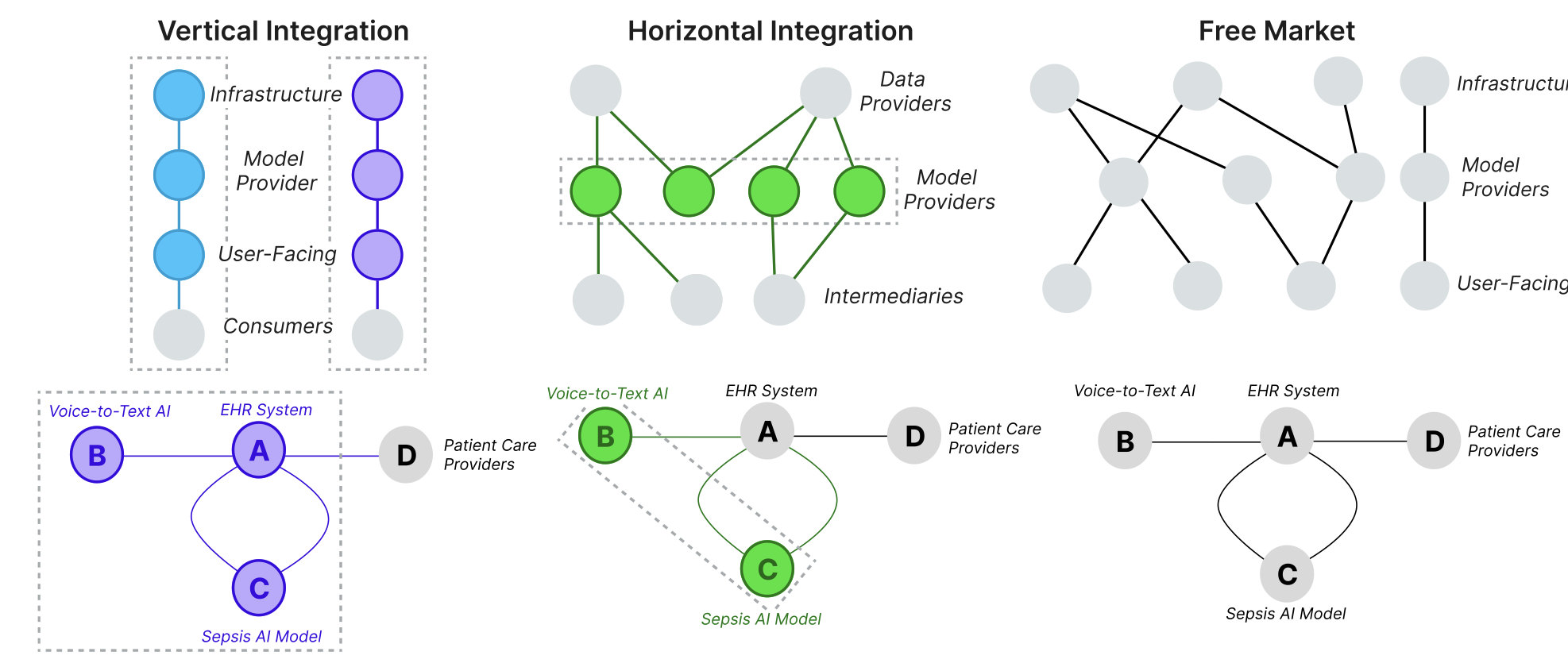
ai supply chains, markets, & redress
AI supply chains are market-structured systems composed of organizations with defined roles, incentives, and contracts. Our work examines how outsourcing, integration, and power dynamics shape avenues of redress for all parties when AI failures occur.
selected
on ai deployment
Our series On AI Deployment discusses the economic and regulatory implications of AI supply chains.
* * * ml interpretability * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * *
selected
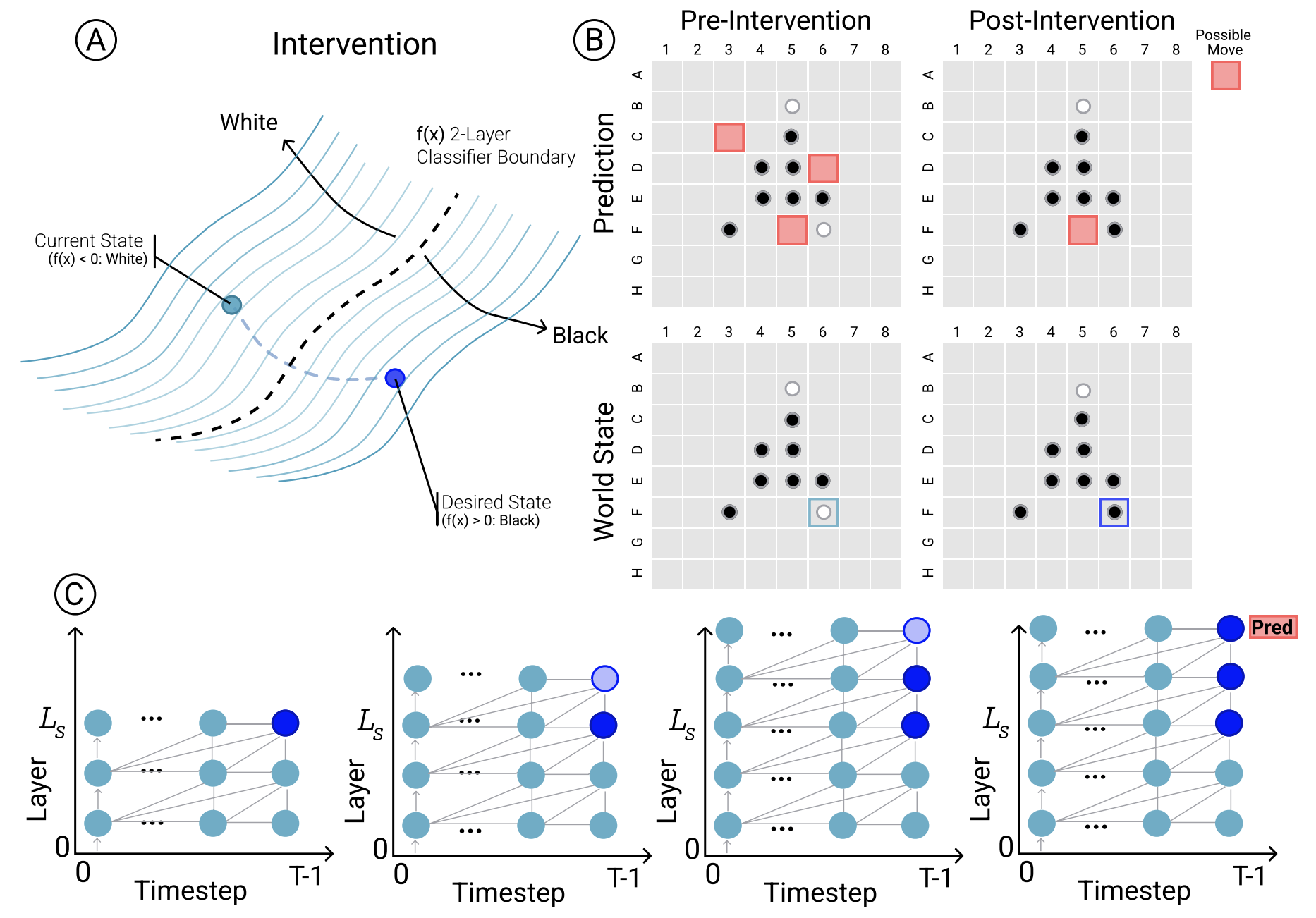
emergent world representations
Do complex LMs memorize surface statistics, or develop internal representations of underlying processes? Using a synthetic board game (Othello), we uncover nonlinear internal representations of board state and show, via interventions, that these are causal. We also create latent saliency maps explaining outputs.
* * * responsible ai* * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * *
selected
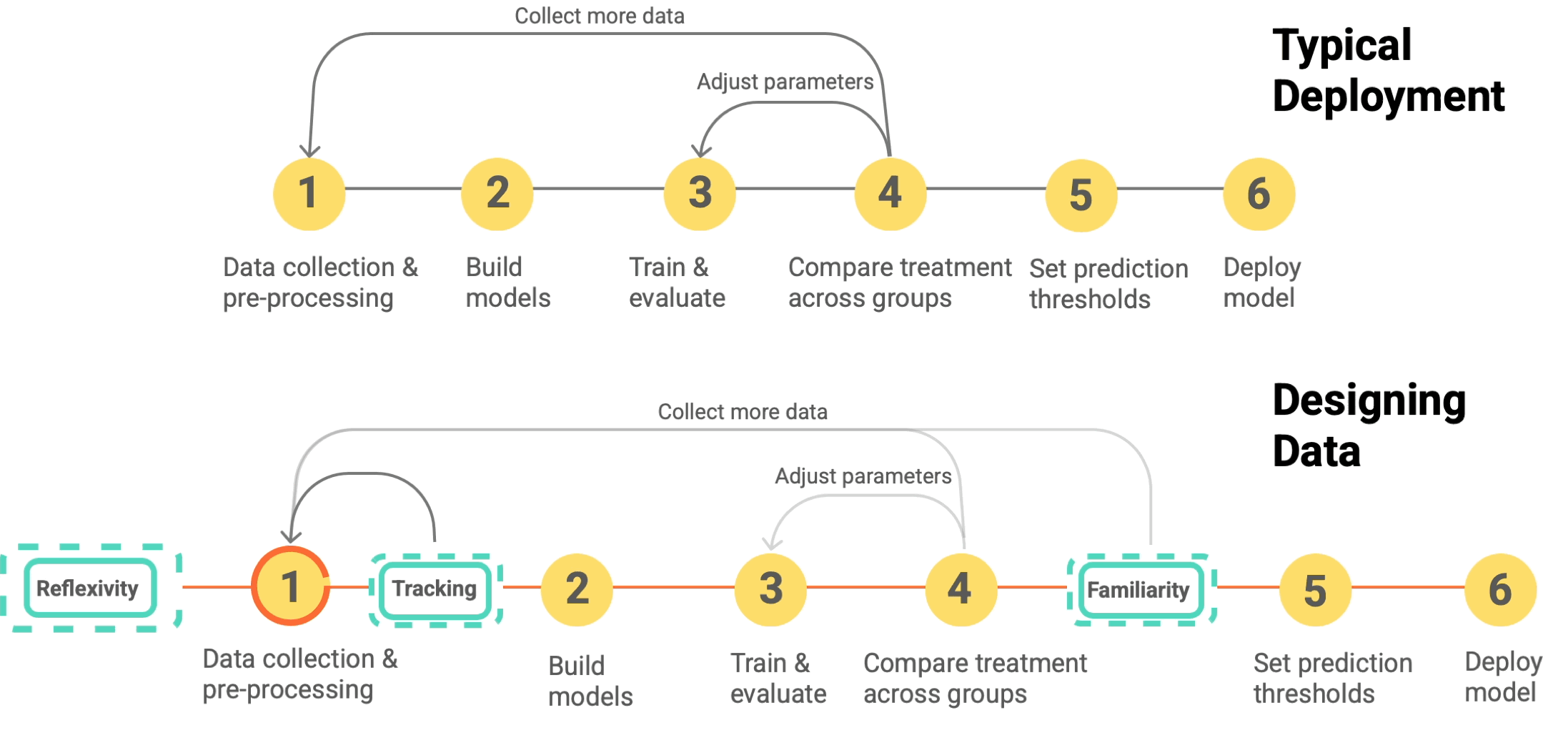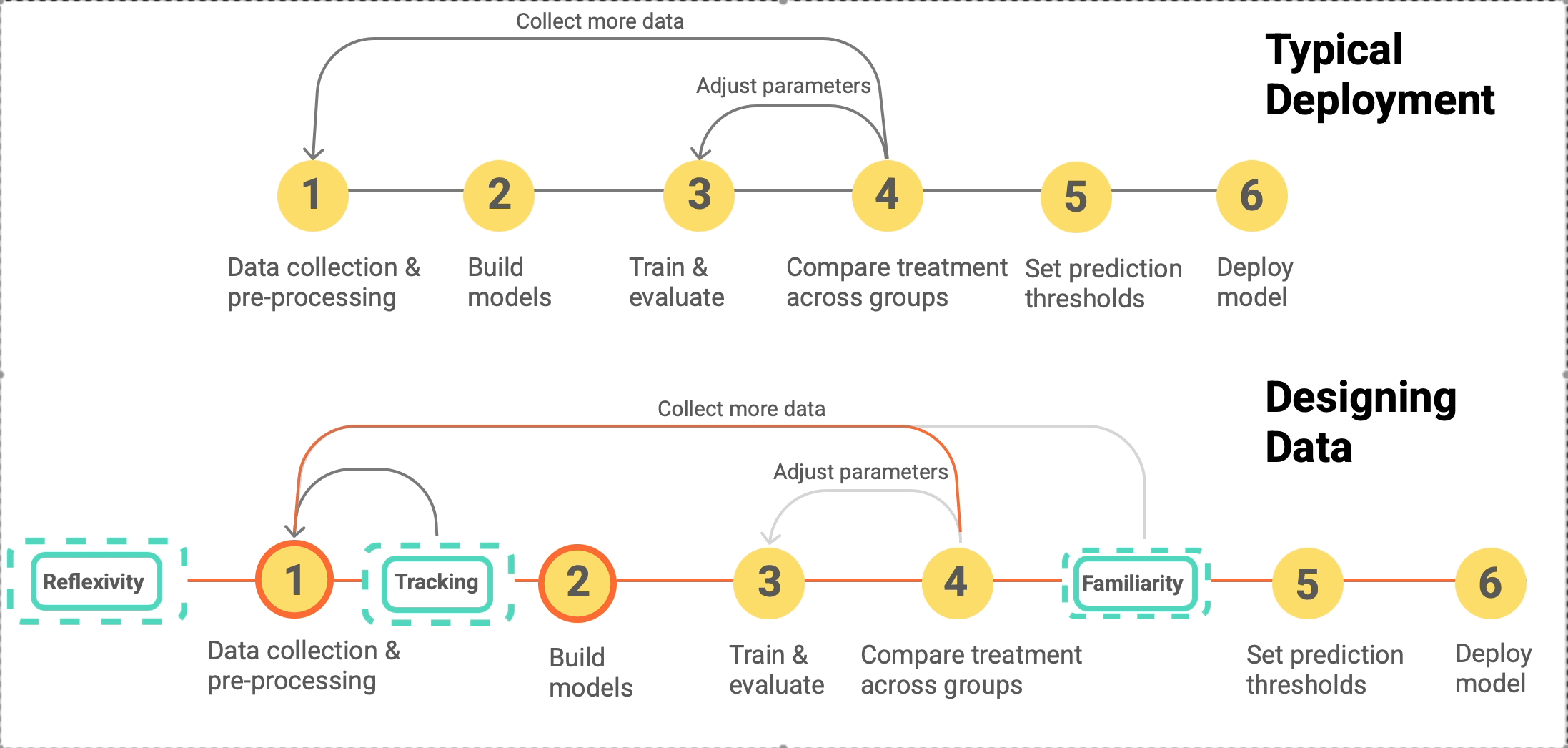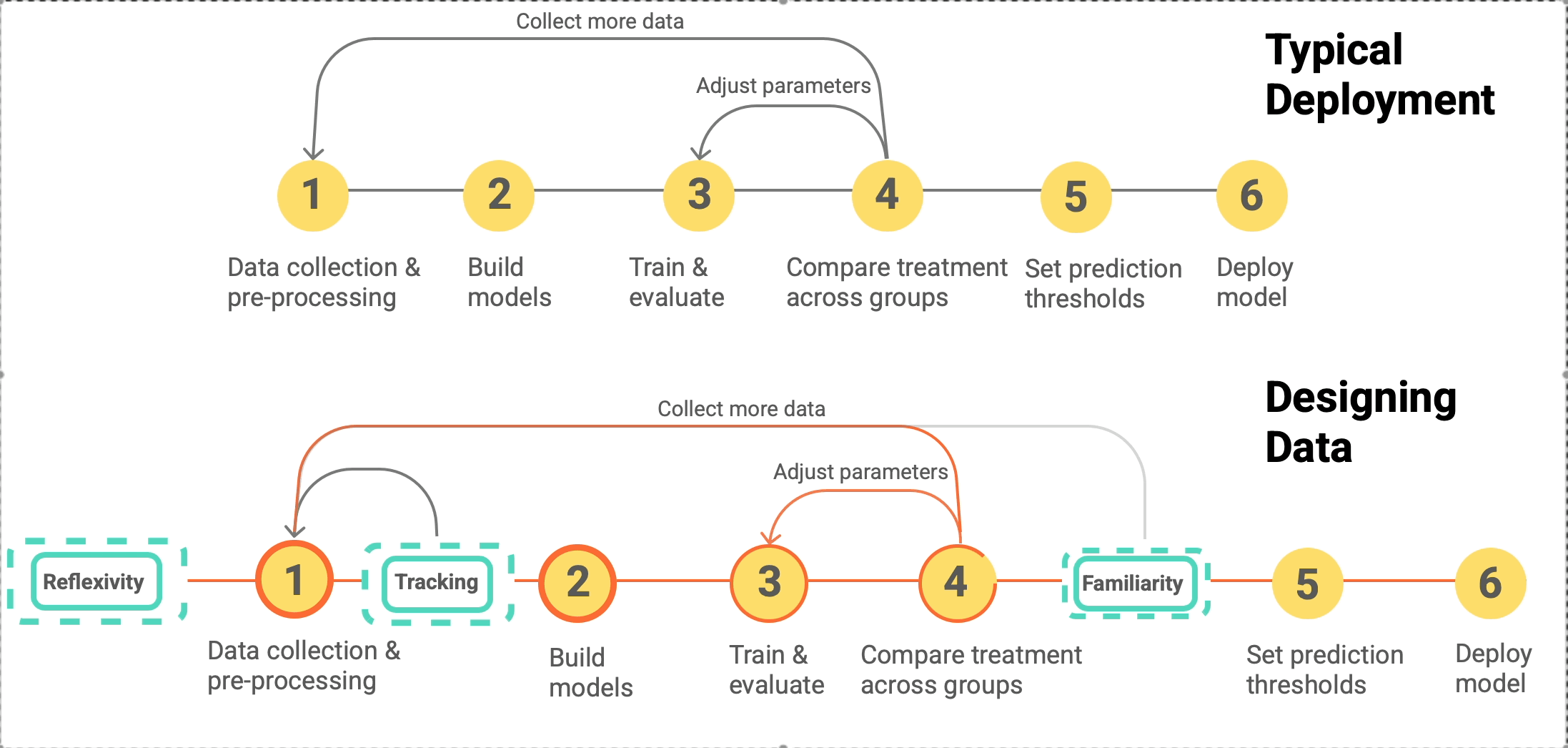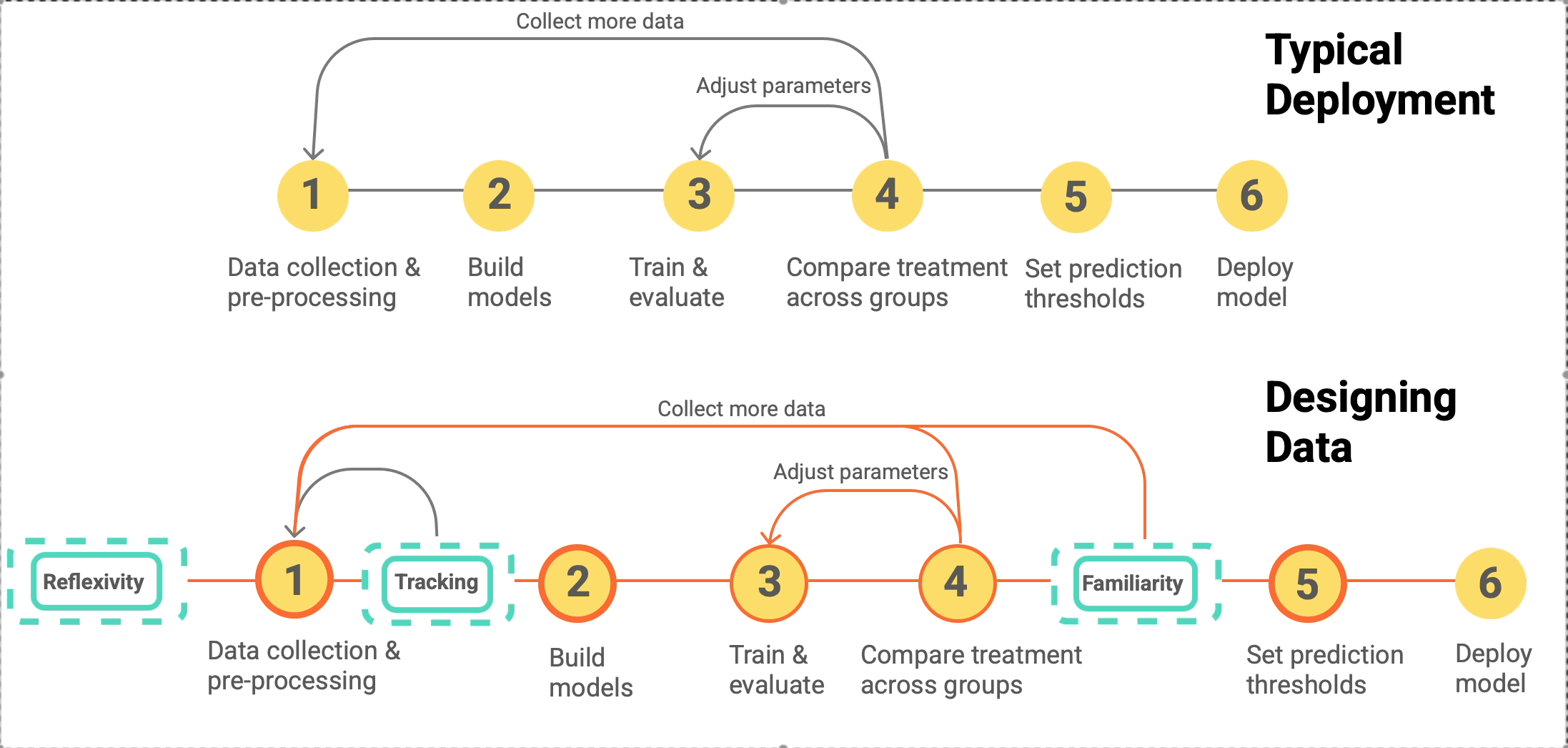
designing data for ml
The ML pipeline includes data collection and iteration. What data should you collect, how should you collect it, and how do you evaluate what a model has learned prior to deployment?
selected
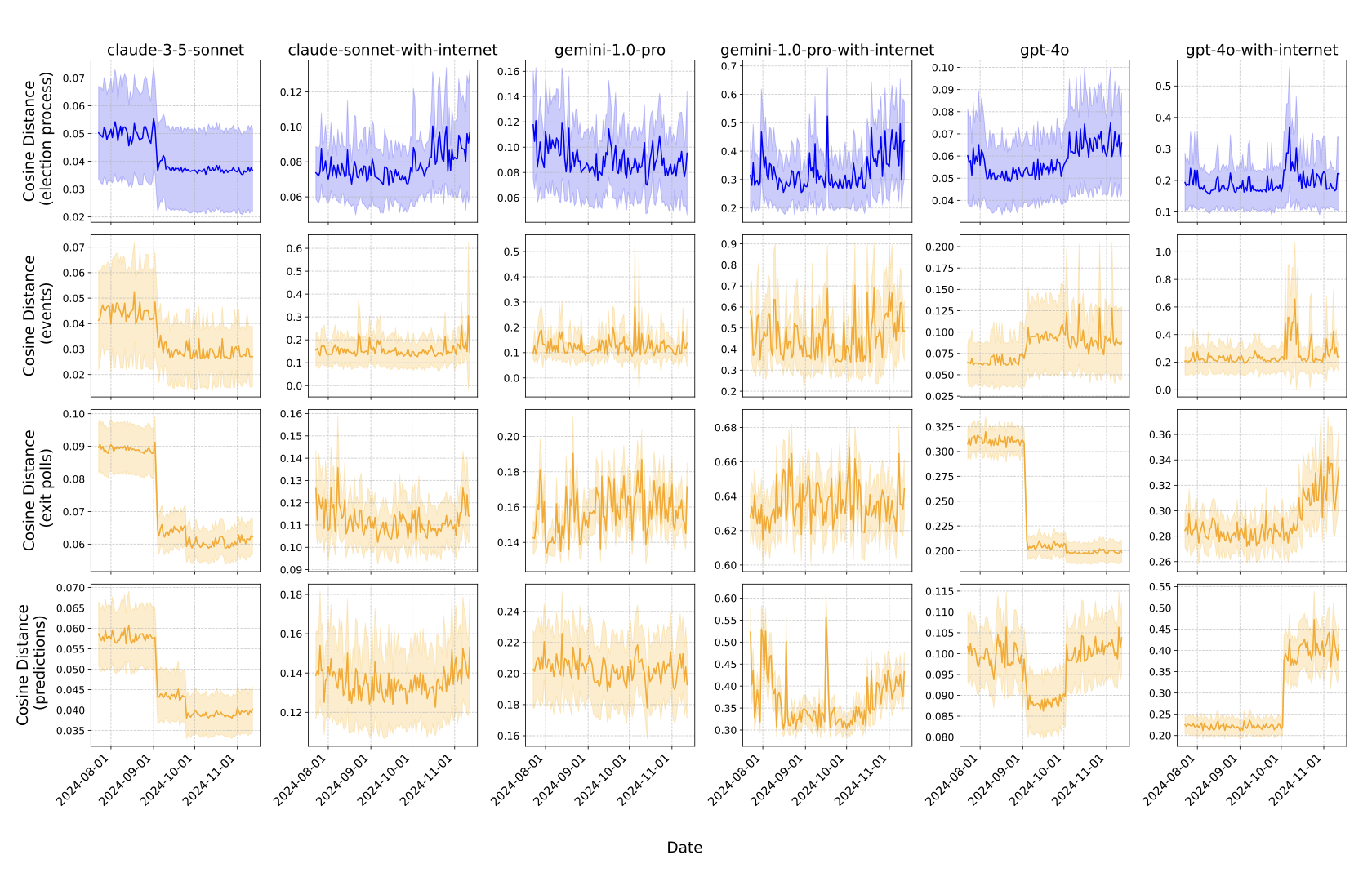
how models evolve over the 2024 election cycle
Large Scale, Longitudinal Study of Large Language Models During the 2024 US Election Season.
selected
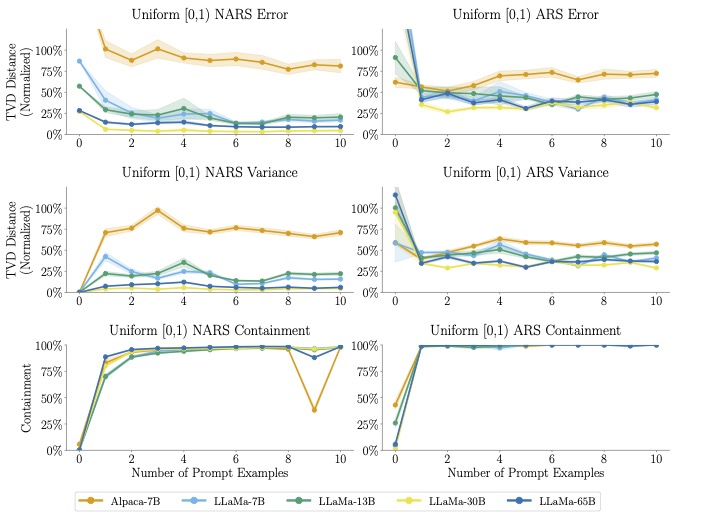
sampling with llms
People have begun using large language models (LLMs) to induce sample distributions for synthetic data, but there are no guarantees about the resulting distribution. We evaluate LLMs as distribution samplers across modalities and find they struggle to produce a reasonable distribution.
selected
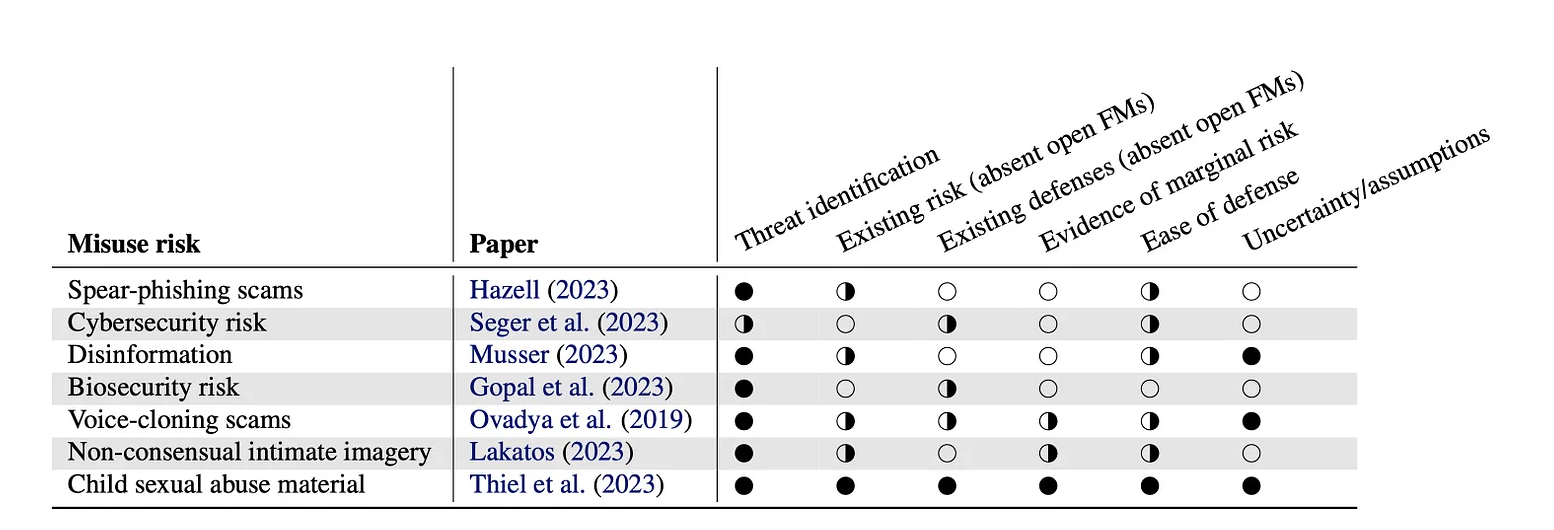
open foundation models
What are the benefits of open models? What are the risks? Led by Sayash Kapoor and Rishi Bommasani, this work collects the thoughts of 25 authors to start answering these questions.
selected
ml practices outside big tech
Support for the democratization of ML is growing rapidly, but responsible ML development outside Big Tech is poorly understood. As more organizations turn to ML, what challenges do they face in creating fair and ethical ML? We explore these challenges and outline research directions in an AIES spotlight paper.
selected
uncertainty in ml systems
ML systems result from complex sociotechnical processes, each introducing distinct forms of uncertainty. Communicating this uncertainty is critical for appropriate trust, but cumulative encodings often obscure its complexity. We explore how and what uncertainty to present to different stakeholders.
selected

socializing data
Labeled datasets are often treated as authoritative ground truth. How is that ground truth determined, and how can we build historical contexts for these systems? This project focuses on collaborative sensemaking and label provenance.
* * * visualizations * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * *
selected
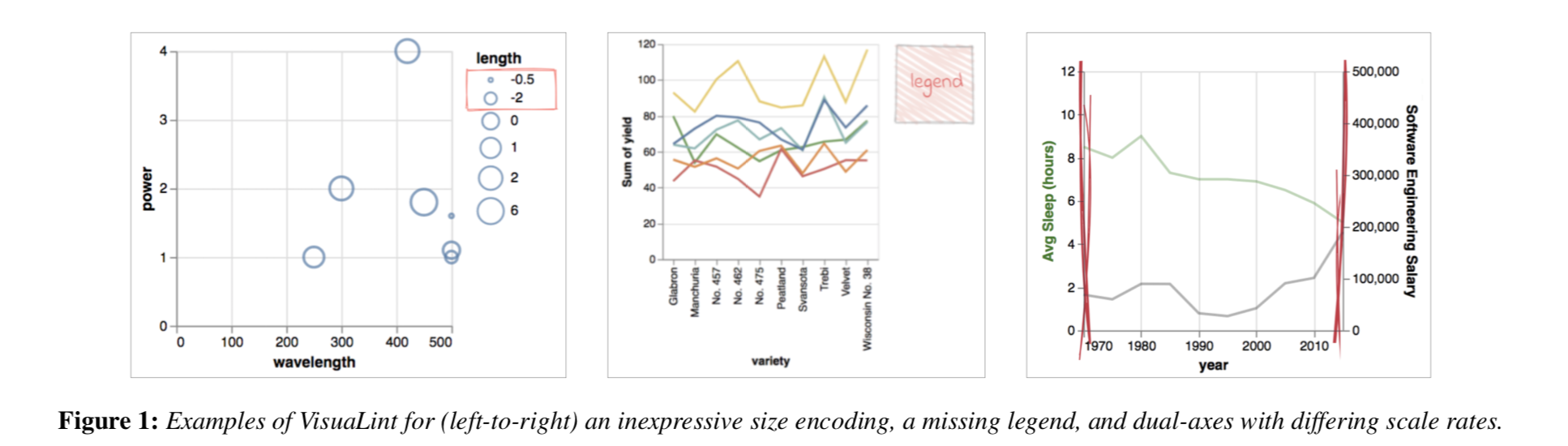
selected